Case Study
Introducing Cartly: An iOS Receipt Tracking App Built on Mnexium
Cartly is an iOS reference application that shows how to ship practical, stateful AI experiences on Mnexium.
Marius Ndini
Founder · Feb 28, 2026
In this demo, we build a receipt-tracking AI application. Users can capture a receipt photo or chat directly with the Cartly assistant to log purchases, track spending over time, and ask follow-up questions about what they bought. Mnexium powers two critical layers in that experience: Memory captures user-specific preferences so responses improve with continued use, and Records persists both receipt-level and line-item data (`receipts` and `receipt_items`, as defined in our schema JSON). Together, these capabilities give the assistant a reliable way to store and retrieve purchase context whenever it needs to answer questions or drive actions.
This architecture is not specific to receipt tracking. It reflects a baseline requirement for most AI applications that need to work beyond a single prompt. Once users expect continuity, personalization, and reliable actions, you need three things at the same time: durable conversation context, memory that can be learned and recalled predictably, and structured storage for business data. Without that system, teams usually end up stitching together separate services for chat history, embeddings, extraction pipelines, schema validation, and data persistence, then spend significant time reconciling mismatches between what the model generated and what the database accepted. In practice, that creates brittle behavior, hard-to-debug failures, and inconsistent user experiences.
In Cartly, Mnexium collapses those moving parts into one request model, which materially reduces delivery time and infrastructure overhead. The same runtime object controls chat behavior, memory controls, identity boundaries, and records synchronization, so the implementation avoids custom orchestration layers, extra middleware, and duplicated retry logic. That shortens development cycles because product and engineering teams can iterate in one surface instead of maintaining multiple pipelines. It also lowers operational cost: fewer components to host, fewer integration edges to monitor, and fewer failure paths in production. The result is faster shipping, simpler maintenance, and a more reliable AI product for end users. We are really trying to deliver all of this in one JSON object appeneded to an existing chatGPT, Claude, or Gemini request.
Why These Features Matter Together
The practical value is the combination: memory-aware chat for context, stable identity for continuity, and records sync for structured persistence. This gives product teams one runtime model for both conversation and business data, instead of maintaining separate paths for response generation and data operations.
In real applications, users do not think in API boundaries. They expect the assistant to remember prior preferences, reference earlier conversations, and take actions on data without losing consistency. AI teams tend to build products & features with the same mindset. When these capabilities are built as isolated subsystems, teams spend time reconciling state drift, fixing partial writes, and debugging context mismatch. By combining identity, memory, recall, and records operations in one request contract, Cartly keeps behavior deterministic, reduces integration overhead, and lets teams ship features faster with less infrastructure complexity.
Why Mnexium Is Powerful In Production
- One runtime contract controls context, persistence, and behavior, so teams avoid fragile cross-service glue code.
- Deterministic records sync reduces mismatches between model output and application state.
- Traceability at the request level makes debugging faster and production behavior easier to trust.
Mnexium Features Used In Cartly
- One `mnx` runtime object per request. Cartly sets behavior in a single place (`history`, `learn`, `recall`, and `records`).Why it matters: behavior is explicit and predictable instead of split across app-level flags.
- Stable identity with `subject_id` + `chat_id`. The app sends durable identifiers on every chat request.Why it matters: conversation continuity survives app restarts and supports true multi-thread chat history.
- Memory controls with history, learn, and recall. Cartly writes memory, recalls it, and keeps prior chat context active.Why it matters: responses stay personalized over time without custom memory orchestration code.
- Records schemas for `receipts` and `receipt_items`. Cartly uses Mnexium Records for typed storage and queryable data.Why it matters: extraction output becomes structured application data that can be filtered and reused.
- `mnx.records.sync=true` for OCR persistence. Receipt parsing and records writes happen in the same request pattern.Why it matters: deterministic writes reduce drift between parsed AI output and stored records.
Demo Flow
The sequence below shows the end-to-end flow in Cartly: schema setup, receipt capture and extraction, record persistence, and the assistant using stored records to answer user questions with grounded context.
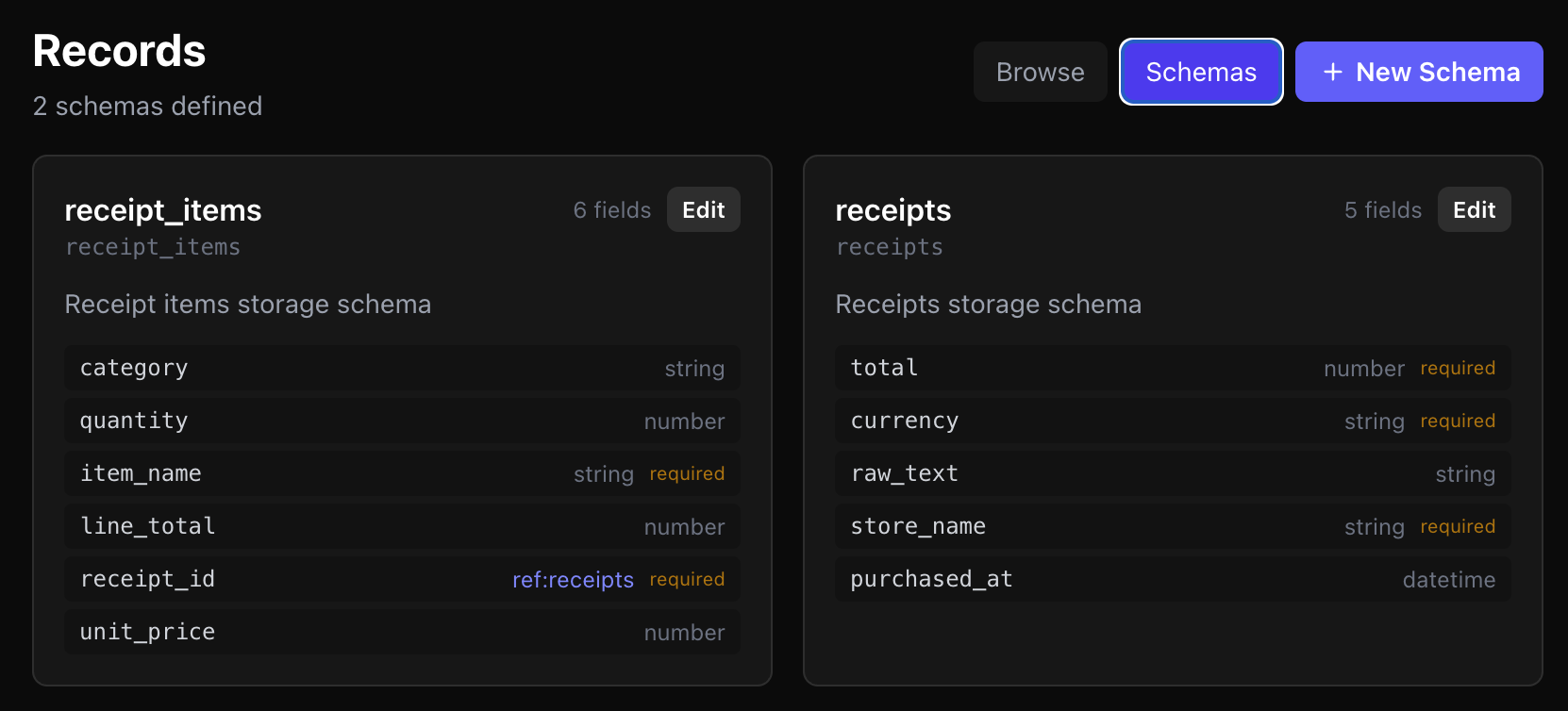
Schema Design
The schema below defines two tables: `receipts` for parent transaction metadata and `receipt_items` for normalized line items linked to each receipt. This structure gives the assistant a reliable relational model for totals, categories, and item-level analysis.
Receipt Capture Demo
Here we capture a receipt image. The AI extracts structured fields, then Mnexium writes both the parent receipt record and related receipt-item records so the data can be queried and reused in future conversations.

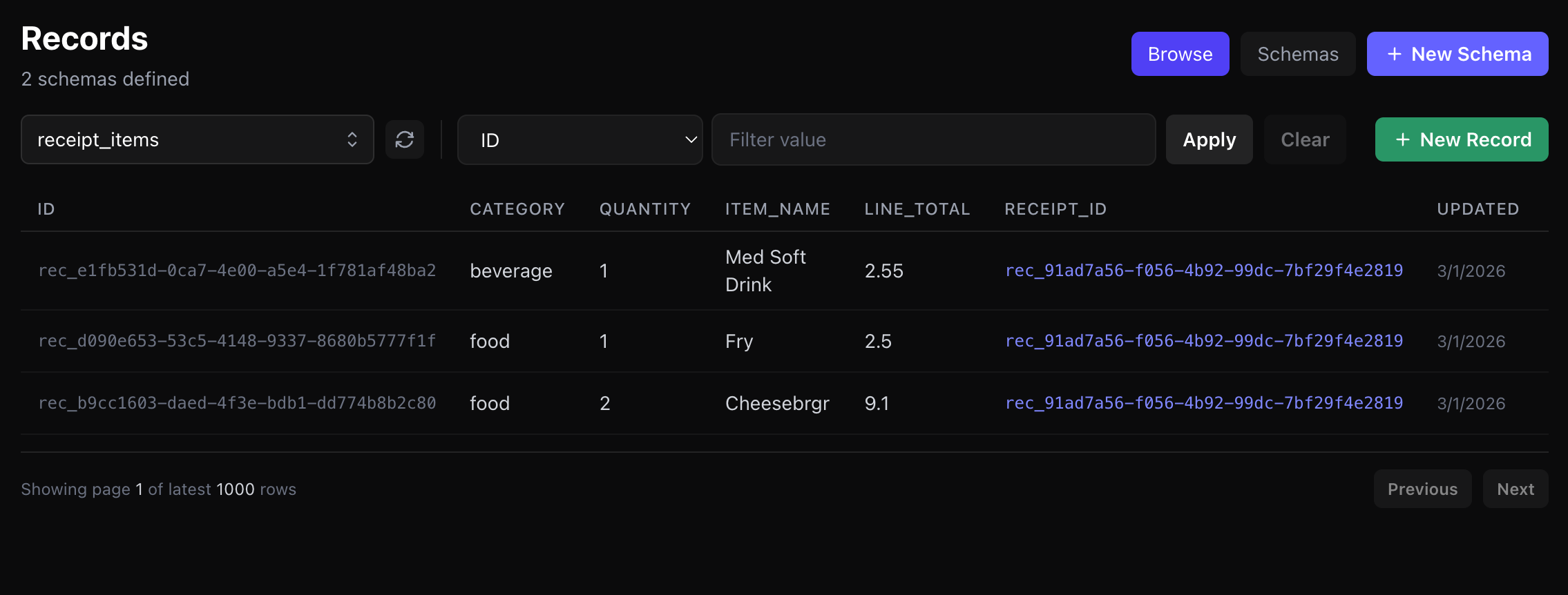
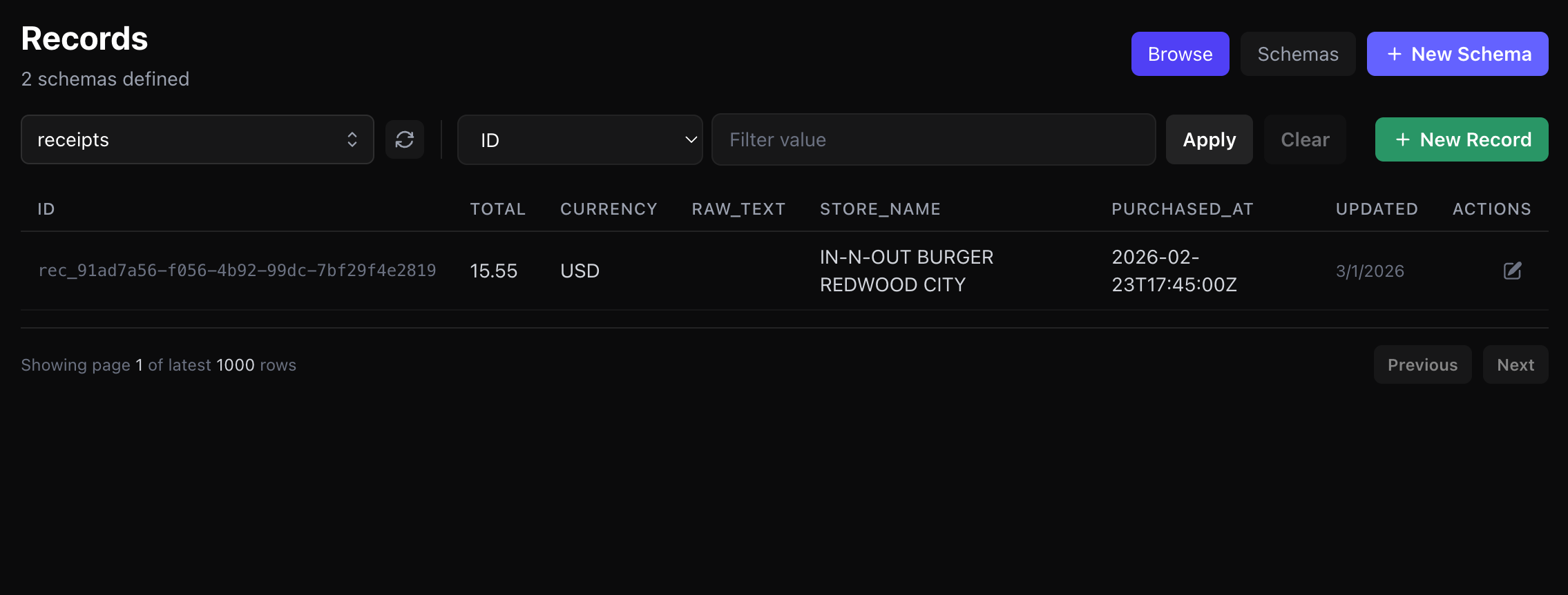
Stored Records In Mnexium
Below are the resulting records stored in Mnexium after the scan flow completes: the parent `receipts` record and the related `receipt_items` records.
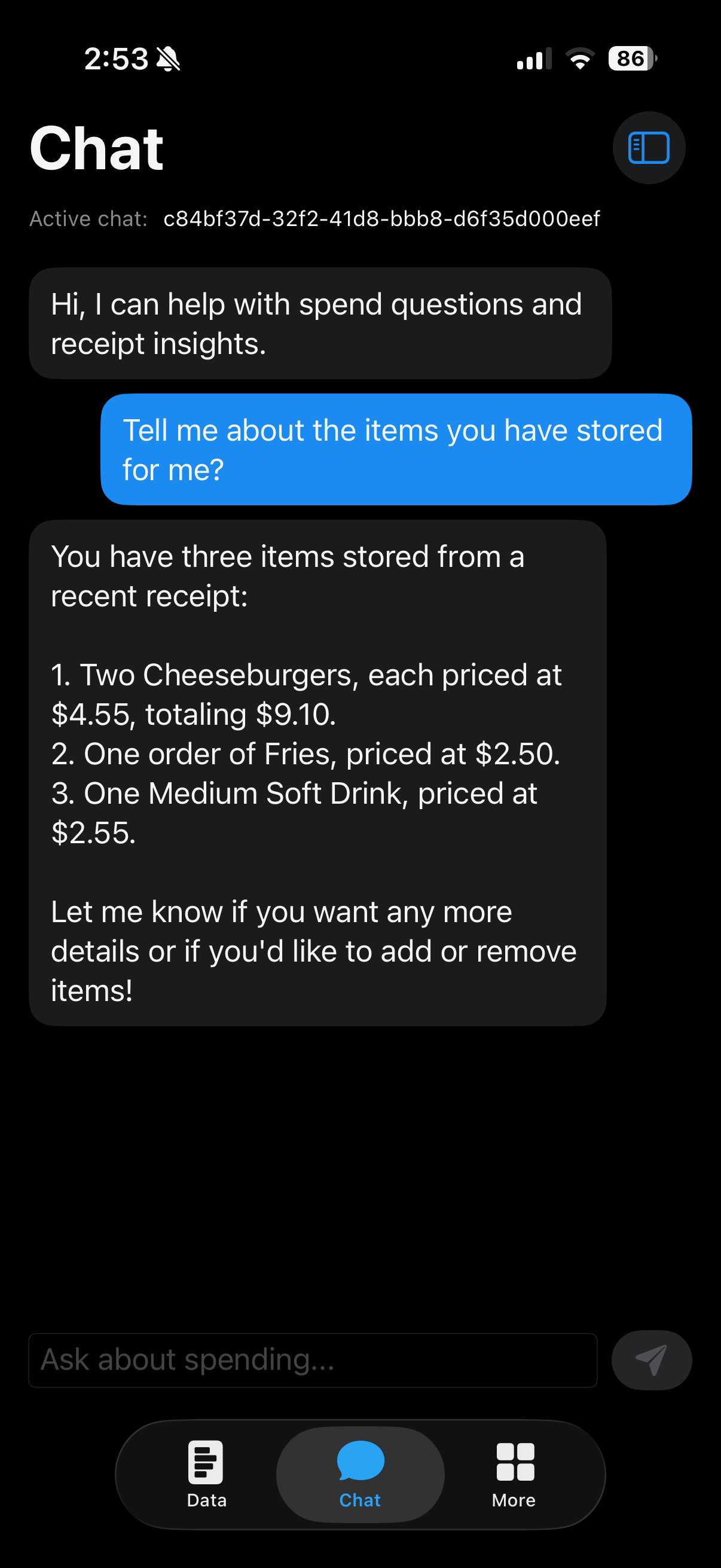
Record-Aware Chat
This view shows the assistant using stored receipt and item records to answer user questions with concrete purchase context, spending details, and item-level information instead of generic responses.
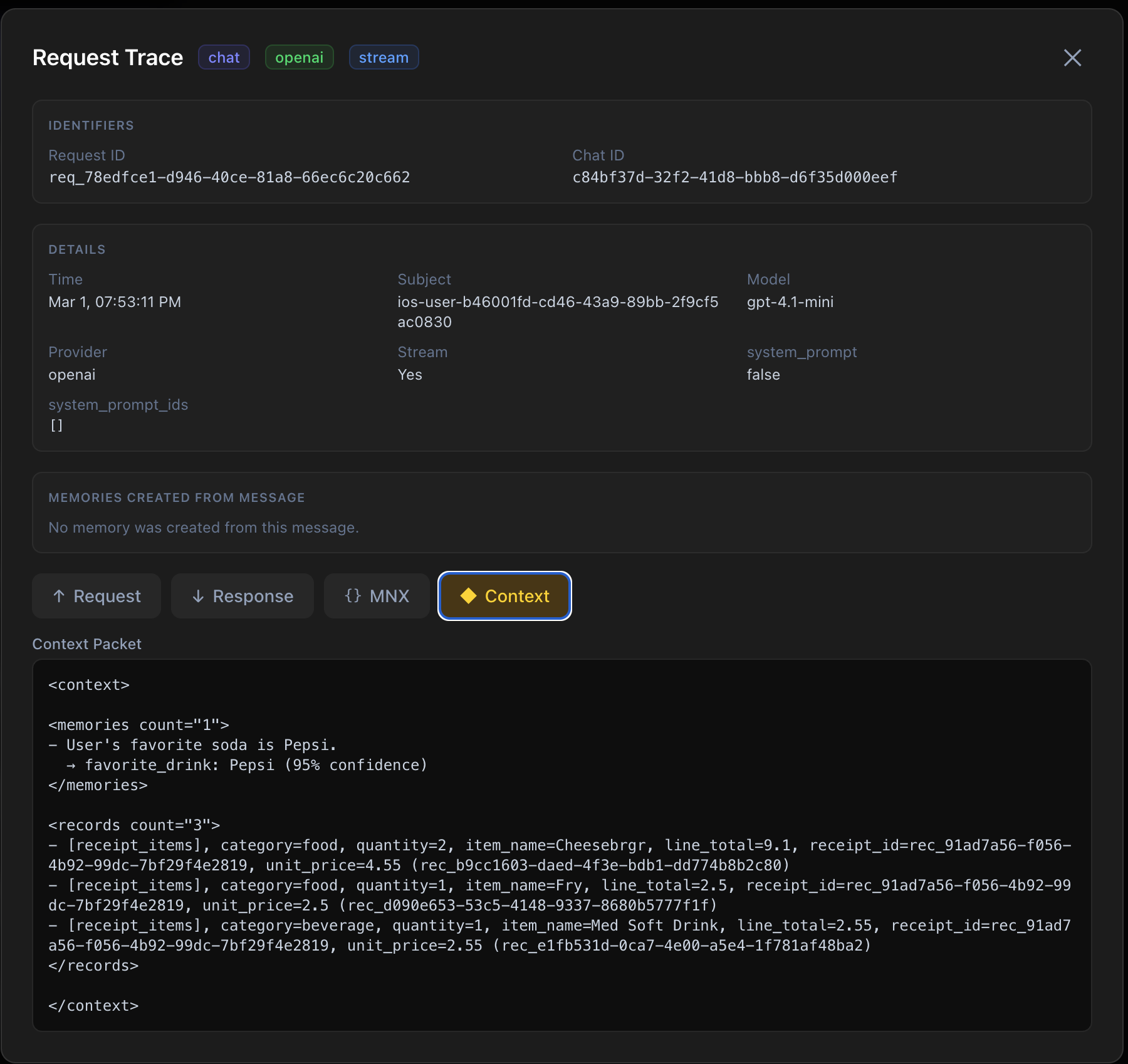
Trace Packet
This trace packet captures the exact runtime context attached to the request, including identity, memory controls, system prompt usage, and records behavior. It gives teams a reliable way to verify what the model actually received, debug behavior quickly, and maintain auditability in production. See request audit APIs.
Core Request Pattern
The request has two layers: the model payload (`messages`, `model`, `stream`) and the Mnexium runtime payload (`mnx`). The model payload describes what the assistant should answer right now. The `mnx` payload describes how the platform should handle identity, memory, context retrieval, and record behavior for this turn.
There is one `mnx` object per request. The records configuration is a nested object inside it (`mnx.records`), not a separate runtime object.
At runtime, Mnexium resolves the effective system prompt, loads optional state, fetches prior chat history, applies summarization if configured, recalls memories and records, and assembles a structured context packet. That packet is injected into the model call so responses are grounded in actual user and purchase history. After the provider responds, Mnexium handles logging, extraction, and record persistence rules according to the same `mnx` configuration.
This is why the request pattern scales well: you do not build separate pipelines for memory, history, and data writes. You configure runtime behavior in one object and receive canonical identifiers (`chat_id`, `subject_id`) and write outcomes back in the response.
{
"model": "gpt-4o-mini",
"stream": false,
"messages": [{ "role": "user", "content": "Parse this receipt" }],
"mnx": {
"subject_id": "ios-user-123",
"chat_id": "5b1e6bae-2694-...",
"records": {
"recall": true,
"learn": "auto",
"sync": true,
"tables": ["receipts", "receipt_items"]
}
}
}Note: `mnx.records.sync=true` is for non-streaming requests so the API can return deterministic record write results in the same response envelope.
- `records.recall`: brings relevant records into context before generation.
- `records.learn` + `records.sync`: controls extraction mode and write guarantees for structured data.
Endpoints Used In The App
- `POST /api/v1/chat/completions`
- `GET /api/v1/chat/history/list`
- `GET /api/v1/chat/history/read`
- `POST /api/v1/records/schemas`
- `GET /api/v1/records/receipts`
- `POST /api/v1/records/receipts`
- `POST /api/v1/records/receipt_items/query`
Project Links
Cartly repository: github.com/mnexium/cartly
Reusable schema blueprint: mnexium-records-schema.json.
Mnexium docs: mnexium.com/docs